Horovod는 openMPI를 기반으로 더 나은 멀티GPUs, 멀티Nodes 환경으로 딥러닝 모델을 훈련시키기 위해 개발되었습니다. 이때 '더 나은' 이라는 말은 코드 생산성, 성능(정확도,Loss), 훈련 효율(걸리는 시간)을 복합적으로 고려한 수식어이며 Horovod의 작동 방식과 Benchmark에 대한 디테일한 내용을 알고 싶다면 여기를 참조하시면 될 것 같습니다.
이 문서는 Docker를 이용한, 2개 이상의 서버를 이용하여 훈련이 가능한 Horovod 설치를 다룹니다.
만약 Docker를 다루는 것이 처음이거나, Docker의 컨셉, 기초 사용법을 잘 모른다면, 이 링크의 영상을 시청하는 걸 추천드립니다. 영상이 좀 길지만 직관적으로 설명을 잘 해줍니다. 만약 영상이 너무 길다면, 밑의 설명에서 따라갈 명령어는 모두 안내되어 있으니 당장 보지 않아도 괜찮습니다.
0. Docker를 선택한 이유
먼저 Horovod를 빌드할 수 있는 환경의 선택지는 다음과 같습니다.
(Horovod는 하나의 패키지라기보다 여러 소프트웨어를 '분산 컴퓨팅'이라는 목적을 위해 끈끈하게 묶어주는 느낌이 강하기에 이후로 '설치'보다 '빌드'한다고 표현하겠습니다.)
-
로컬에 설치
-
파이썬 virtualenv 을 이용한 가상환경 생성
-
Anaconda를 이용한 가상환경 생성
-
Docker Image로 Container 생성
-
이외에 Spark, LSF는 잘 모르기 때문에 Pass
0.1) 설치방법 1, 2번은 추천드리지 않습니다.
알아두어야 할 것이 Horovod는 버전 호환에 있어서 '매우 취약'합니다. 빌드된 호로보드 환경에서 일부 패키지의 버전을 바꾼다던지 추가 패키지를 잘못 설치하면, 동작이 되지 않거나 빌드를 다시 해야하는 경우가 흔하게 발생합니다.
조금 디테일하게 설명하자면, Horovod는 'GPU를 사용하기 위한 CUDA Driver'와 'CUDA Toolkit’, ‘딥러닝 프레임워크’, ‘OpenMPI’ (+NCCL) 와 같은 소프트웨어를 모두 설치한 상태에서 함께 돌아가게 하기 위해서 빌드를 해주어야 하고, 버전 변경이 그다지 자유롭지 않습니다. 더군다나 자동으로 처리되지 않는, 설정해주어야 하는 PATH가 부지기수입니다.
따라서 빌드가 안될 때, 기존에 사용하던 환경이 Horovod와 안 맞는 버전이 무엇인지 찾기도 어렵고, 또 Horovod 빌드를 위해서 기존 환경을 쓰지 못하게 되는 경우도 발생할 것입니다.
0.2) Anaconda를 이용한 설치
Anaconda를 이용한 설치는 좀 더 편하게 가능할 것으로 보이지만, 저는 끝까지 진행해보지 않았습니다. Anaconda로 진행한다고 해도, PATH, PYTHONPATH, cuda관련 PATH와 같은 부분은 주의 깊게 설정해주어야 합니다.
0.3) (Recommended) Docker를 이용한 설치
Docker를 이용하면, 내가 원하는 환경에 따라 호로보드에서 제공하는 Docker Images를 받아오기만 하면 되고, Container에 OS부터 설치가 되는 것이기 때문에 로컬 환경에 영향을 거의 주지도, 받지도 않습니다.
때문에, 컨테이너가 망가졌을 때나, 새로운 버전이 필요할 때, 설치를 잘못하여 재설치가 필요한 때, 여러 Container를 유지하며 개별로 작업하고 싶을 때, 모든 경우에 빠르게 대응할 수 있다는 장점이 있습니다.
단점이라면 Docker를 좀 능숙하게 다룰 줄 알아야 일이 편해질 것 같다..? 정도입니다.
1. Prerequisite
Horovod 빌드 전에 준비해야할 점들입니다.
사전 준비는 크게 3가지 스텝으로 나눌 수 있습니다. (순서는 상관없습니다.)
-
Nvidia-driver 설치
-
.ssh 설정
-
Network interface name 통일
1-1. Nvidia-driver 설치
*위 그림은 nvidia-docker 깃허브 페이지에서 가져온 그림입니다.
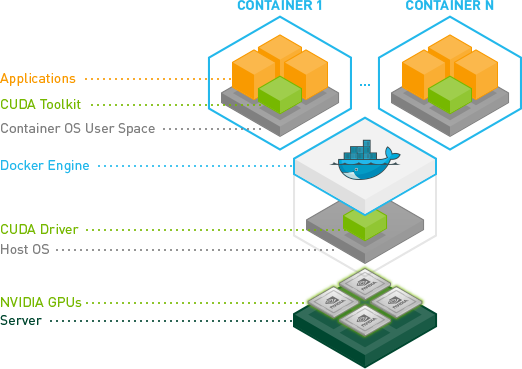
먼저 헷갈릴 것 같은 nvidia-docker와 nvidia-driver를 구분 짓고 넘어가자면,
nvidia-driver 는 위 그림의 CUDA Driver에 해당하는 부분으로 Host OS 즉, 내 로컬 환경에서 GPU를 인식하고 사용할 수 있게 해주는 driver입니다. (CUDA Toolkit, cudnn은 그 위에 올라가는 라이브러리 개념의 소프트웨어로 Docker 컨테이너 내부에서 설치됩니다.)
nvidia-docker 는 Docker Engine에서 컨테이너를 생성하면 기본적으로 각 컨테이너는 nvidia GPU를 인식하지 못하기 때문에 Horovod가 빌드될 컨테이너가 GPUs를 인식할 수 있도록 해주는 Base 컨테이너입니다. 설치는 뒷부분에 다시 설명합니다.
만약 Nvidia GPU가 달려있는 서버나 컴퓨터를 사용하고 있다면, 당연히 nvidia-driver가 깔려있을 것이고, CUDA Toolkit과 cudnn도 설치하여 사용하고 있을 것입니다.
안타깝게도 Horovod를 성공적으로 빌드하기 위해선 사용한 딥러닝 프레임워크 버전에 따라 다른 nvidia-driver를 설치해 주어야 합니다. (즉, TF2를 사용하다가 TF1.14를 사용해야 한다면, nvidia-driver를 재설치한 뒤 tf1.14 horovod를 빌드해야 하고, 이 시점부터 TF2 컨테이너는 사용할 수 없게 됩니다.)
원하는 프레임워크와 호환되는 버전을 체크해봅니다.
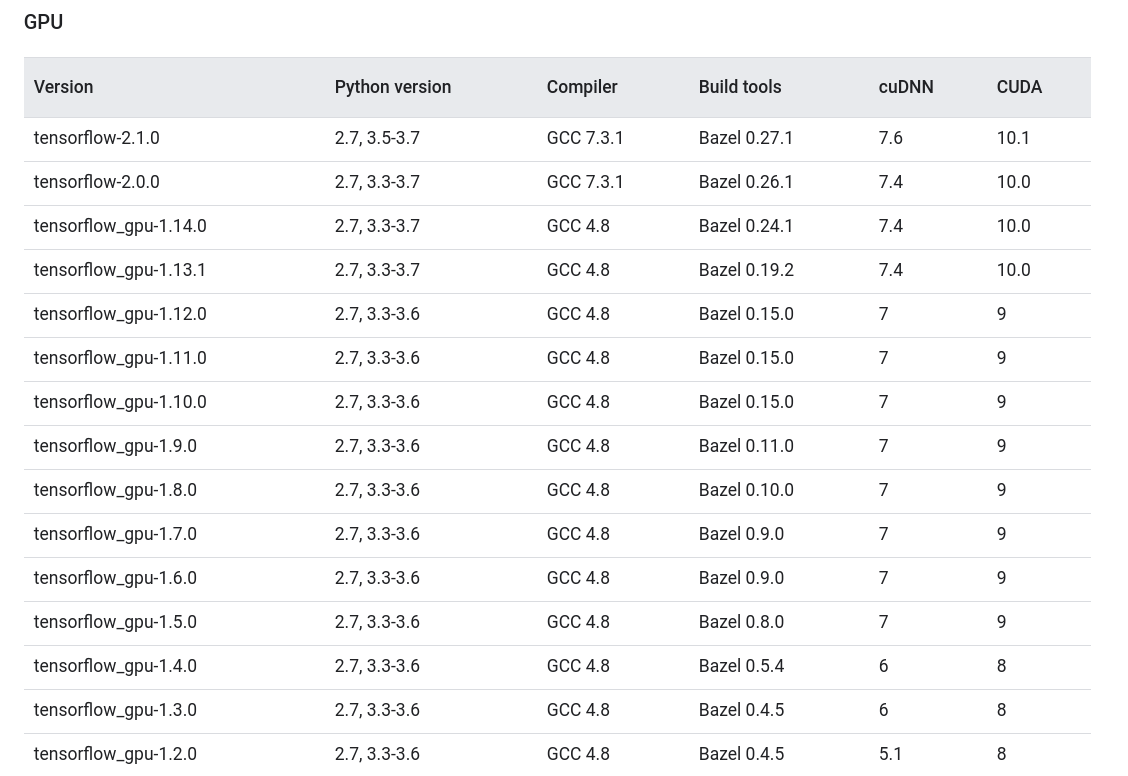
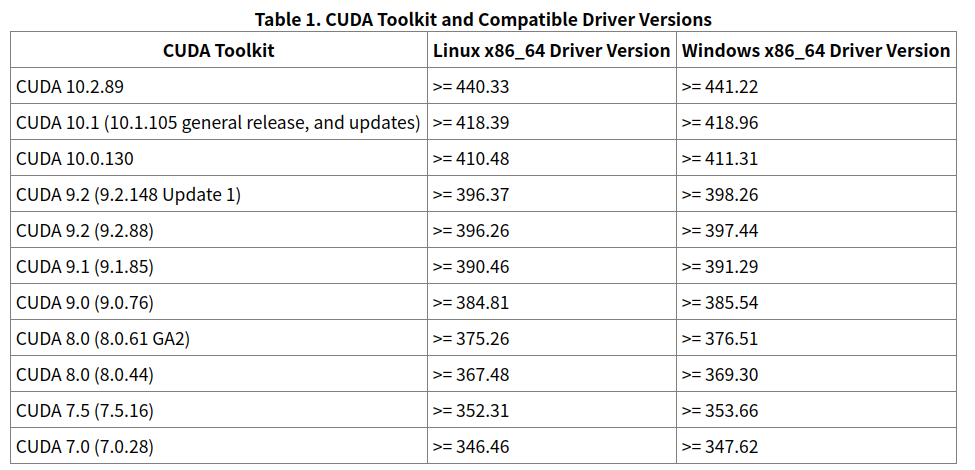
만약 필요한 nvidia-driver가 이미 깔려있다면, 다음 단계를 패스해도 좋습니다.
Horovod를 사용하다보면 여러번 nvidia-driver를 지웠다 설치하게 되는데, 재설치 후 사용에 문제가 없도록 가능한 깔끔하게 지우고 설치하는 것이 필요합니다. 다음 명령어를 따라갑니다.
[nvidia-driver를 재설치해야 하는 경우]
-
먼저 다음 명령어를 모두 실행하여, cuda, nvidia관련 패키지를 모두 삭제하고 잔여 기록까지 청소해줍니다.
dpkg -l | grep cuda- | awk '{print $2}' | xargs -n1 sudo dpkg --purge
sudo apt-get purge nvidia*
sudo apt-get -f install
sudo apt autoremove
sudo dpkg --configure -a
sudo apt-get clean
-
그 다음, 구 버전의 nvidia-driver를 설치할 수 있도록 ppa 채널을 추가해준 뒤 nvidia-driver-(version)을 설치해 줍니다.
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo apt install nvidia-driver-{version}
이 때 모든 version이 설치가 가능한 것은 아니고 몇 개의 설치가능한 버전이 남아있는 것인데, Tensorflow 기준으로
CUDA 10.1 -> nvidia-driver-430
CUDA 10.0 -> nvidia-driver-418
CUDA 9.x -> nvidia-driver 390 or 418
로 설치하면 제가 경험상 잘 빌드되었습니다.
1.2 SSH 설정
멀티머신으로 동작할 서버들은 모두 서로 password 없이 root로 접속할 수 있어야 합니다.
su 명령어를 통해 root 계정으로 들어간 뒤, cd ~/.ssh 로 이동하여 다음 링크의 단계를 그대로 따라가 줍니다.
http://www.linuxproblem.org/art_9.html
[해석 어려울 시]
서버 A와 B가 있다고 할 때, A와 B의 root계정에서 각각
$ ssh-keygen -t rsa
… 패스워드 없이 enter 3번.
… 키 생성 완료
[클립보드를 공유하고 있다고 가정하였습니다.]
A$ cd ~/.ssh
B$ cd ~/.ssh
A$ vi id_rsa.pub //A의 public key를 복사
B$ vi authorized_keys //B의 authorized_keys에 붙여넣기.
B$ vi id_rsa.pub //B의 public key를 복사
A$ vi authorized_keys //A의 authorized_keys에 붙여넣기.
A$ ssh [-p port] root@{B’s IP address} //서로 한번씩 ssh로 접속하여 known_hosts에 등록.
B$ ssh [-p port] root@{A’s IP address}
여기까지 하면, A, B의 non-password setting이 끝납니다.
3개 이상의 서버를 연결할 때도 각 서버가 나머지 모든 서버에 대해 통신할 수 있도록 셋팅해줍니다.
1.3 Network interface 통일
Horovod를 실행할 때, Master 노드가 Slave노드 모두에게 똑같은 명령을 전달해 주는데, 이때 network-interface 이름을 하나로 지정하여 전달해주기 때문에, 모든 노드들의 Network Interface이름은 같아야 합니다.
Ubuntu 18.04 기준으로 Network Interface name을 변경하는 법은 다음과 같습니다.
-
현재 Network Interface의 MAC Address를 기록해둡니다.
$ ip addr
-
다음 위치에 70-persistent-net.rules 파일을 생성합니다.
$ sudo vi /etc/udev/rules.d/70-persistent-net.rules
내용은 다음과 같습니다. 보라색으로 표시된 부분은 위에서 기록한 MAC address, 원하는 Interface Name을 입력해줍니다. 만약 id addr에서 출력된 MAC address가 2개 이상이라면 각각에 모두 이름을 붙여주되, 메인으로 통신하는 Interface 이름만큼은 통일해 줍니다.
“70-persistent-net.rules”
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="xx:yy:xx:yy:xx:yy", ATTR{dev_id}=="0x0", ATTR{type}=="1", NAME="INTERFACE NAME"
ex)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*", ATTR{address}=="4c:ed:fb:91:b5:35", ATTR{dev_id}=="0x0", ATTR{type}=="1", NAME="eth0"
-
/etc/netplan/filename.yaml 파일에 들어가 network interface name 부분(보라색)을 수정해줍니다. 만약 filename.yaml이 없더라도 당황하지 말고, /etc/netplan/50-cloud-init.yaml을 찾아 내용만 변경해주시기 바랍니다.
$sudo vi /etc/netplan/filename.yaml or
$sudo vi /etc/netplan/50-cloud-init.yaml
ex) “filename.yaml or 50-cloud-init.yaml”
# This file is generated from information provided by
# the datasource. Changes to it will not persist across an instance.
# To disable cloud-init's network configuration capabilities, write a file
# /etc/cloud/cloud.cfg.d/99-disable-network-config.cfg with the following:
# network: {config: disabled}
network:
ethernets:
eth0:
dhcp4: no
addresses: [192.168.60.12/24]
gateway4: 192.168.60.1
nameservers:
addresses: [203.248.252.2, 164.124.101.2]
version: 2
-
GRUB configuration file을 다음 부분을 찾아 수정합니다.
$ sudo vi /etc/default/grub
From:
GRUB_CMDLINE_LINUX=""
To:
GRUB_CMDLINE_LINUX="net.ifnames=1 biosdevname=0"
-
Update 합니다.
$ sudo update-grub
(Optional)
$ sudo update-initramfs -u
$ reboot
2. 설치
이제 사전 준비가 모두 끝났습니다. 먼저 Docker가 설치되어 있지않다면, 설치해줍니다. (최신 버전으로 업데이트해줍니다.)
$ curl -fsSL https://get.docker.com -o get-docker.sh
$ sudo sh get-docker.sh
위에서 설명하였던, nvidia-docker를 설치하여 줍니다. 공식링크<-
# Add the package repositories
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
$ sudo systemctl restart docker
-
컨테이너를 생성
$ su
$ cd ~
$ mkdir horovod-docker-gpu
$ wget -O horovod-docker-gpu/Dockerfile https://raw.githubusercontent.com/horovod/horovod/master/Dockerfile.gpu
$ docker build -t horovod:latest horovod-docker-gpu
위 명령어로 Image를 빌드하면, 쿠다 10.1에서 동작하는 최신 버전의 딥러닝 프레임워크 패키지가 설치되는데, 만약 원하는 구성이 있다면, Dockerfile을 수정하거나, 다음 링크에서 원하는 환경의 pre-build된 이미지를 가져올 수 있습니다.
Dockerfile 다른 예시: https://github.com/ChanWoo25/my_dockerfile
Pre-build된 Image: horovod/horovod Tags
$ docker run --gpus all -it --network=host -v /root/.ssh:/root/.ssh -v /root/source:/root/source --name horovod_1 horovod:latest
[명령어 분석]
docker run : 컨테이너를 최초 생성함과 동시에 실행시키는 명령어
--gpus all : nvidia-docker를 설치한 뒤에 사용가능한 옵션, 컨테이너에 할당할 GPU의 갯수를 설정한다. 만약 호스트에 달려있는 4개의 GPU 중에 2개만 할당하고 싶다면, --gpus 2 // 특정한 GPU를 할당하는 것도 가능하다.
--it : 컨테이너 안으로 들어가 명령을 입력, 실행하고 터미널로 결과를 볼 수 있게한다.
--network=host : 호스트의 네트워크 인터페이스를 가져와 사용할 수 있게 해주는 인자.
-v /root/.ssh:/root/.ssh : [1.2]에서 설정한 ssh 셋팅을 이용하여 멀티머신 통신을 할 수 있게 해준다.
-v /root/source:/root/source : /root/source 에 컨테이너 안과 밖에서 동시에 유지하고 싶은 파일들을 집어넣는다. -v 인자를 사용하면, 호스트의 폴더를 컨테이너 안에 마운트 시킬 수 있는데, 마운트된 파일들을 수정할 시, 연결된 호스트의 파일에도 영향을 주고, 컨테이너 삭제시에도 그대로 유지된다.
--name horovod_1 : 컨테이너를 구분하는 고유의 이름
horovod:latest : 컨테이너를 생성하기 위해 사용할 이미지:tag
-
example 코드 돌리기.
컨테이너가 잘 생성되었다면, /example 디렉토리로 들어와 있을텐데, Slave역할을 할 컨테이너들에서 모두 다음 명령어를 실행합니다. 포트 12345를 이용하여 ssh 통신을 허용한다는 뜻입니다.
$ bash -c "/usr/sbin/sshd -p 12345; sleep infinity"
그 다음 Master 노드의 컨테이너에서 Slave노드들에 접근하여 동작이 되는지 확인합니다.
-np인자에 총 사용할 GPU 갯수를 넣고, -H 인자로 각 노드의 ip:{개수},... 형식으로 GPU를 할당합니다. -H 에서 총 GPU의 개수가 당연히 -np 랑 맞아야 합니다.
--network-interface 에서 [1-3]에서 통일시켰던 네트워크 인터페이스 이름을 넣어줍니다.
그 다음 python을 런타임으로 하여 Horovod가 적용된 .py 파일을 실행시켜줍니다.
$ horovodrun -np 8 -H localhost:4,{slave’s IP}:4 -p 12345 --network-interface eth0 python tensorflow2_keras_mnist.py
#부록
[horovodrun 시 ip주소를 매번 적지 않고 싶을 때]
$ vi /etc/hosts 에 들어가 ip주소를 이름으로 지정한다.
ex) “/etc/hosts”
127.0.0.1 localhost.domain localhost
127.0.1.1 qsvr6
192.168.60.106 qs6
192.168.60.101 qs1
192.168.60.103 qs3
192.168.60.102 qs2
…
[horovodrun이 mpirun으로 해석된 명령 EX]
$ mpirun --allow-run-as-root -np 12 -H qs2:4,qs3:8 -bind-to none -map-by slot -mca pml ob1 -mca btl ^openib -mca plm_rsh_args "-p 12345 -v" -mca btl_tcp_if_include eth0 -x NCCL_SOCKET_IFNAME=eth0 python tf2_cifar100.py
'Ubuntu' 카테고리의 다른 글
| Ubuntu 18.04 에서 한글 키보드, 한영키 설정하기 _ NAMU (0) | 2020.08.08 |
|---|

댓글